

Your Lunch Break Primer on Generative AI
How VAEs, GANs, and diffusion models cook up content


Have you ever tried to stump an AI model with the strangest prompt you can imagine? The other day, I asked Chat GPT to draw a beaver in a Mountie uniform juggling syrup bottles atop Niagara Falls, and it obliged without blinking.
In this short primer, we will lift the hood on today’s generative models a bit to see how they weave randomness into creativity and learn the limits that designers and researchers must keep in mind when using AI as a partner.

Predict versus Produce: Where Generative AI Leaps Ahead
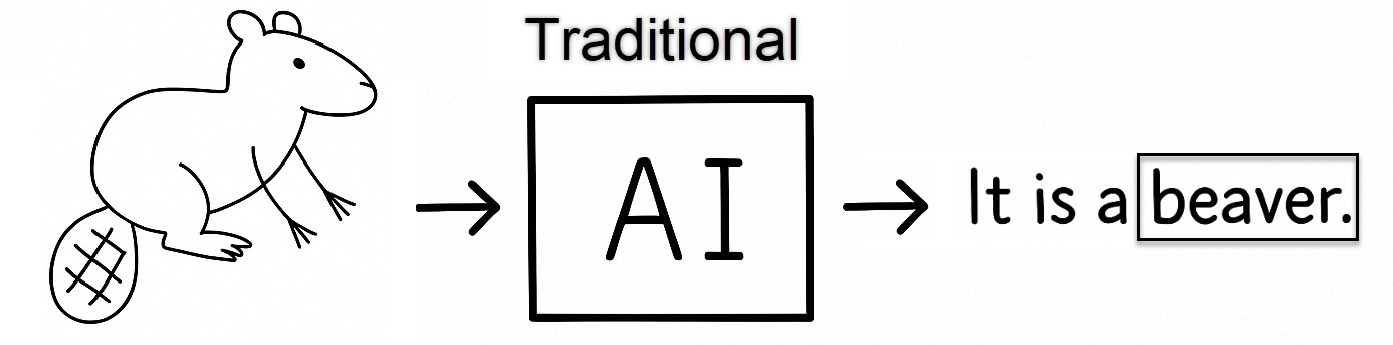
Traditional AI models, often called machine learning models, usually tackle a single, clear task: predicting or classifying data. For example, we might give the model an image and ask it to decide, or classify, whether it shows a “beaver” or a “cat.”
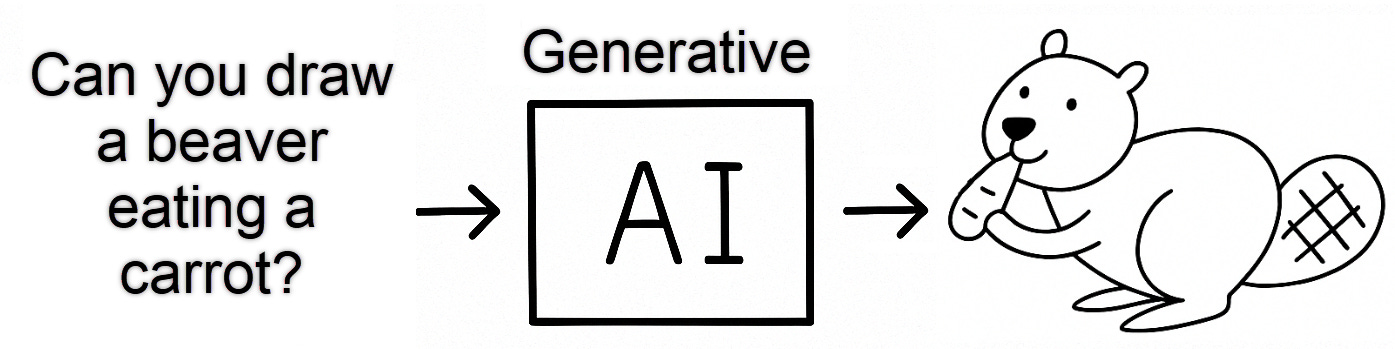
Generative AI goes a step further by learning to create new content, not just prediction or classification; it can produce a fresh picture that resembles a beaver or a cat, or even generate a paragraph or haiku poem that describes beavers, cats, or countless other things. Your command (prompt) is generative AI’s wish.
This is a big accomplishment in the world of design because it reshapes creation, art, and intellectual property paradigms. It also lets designers iterate rapidly, explore wider idea spaces, and collaborate with AI as a co-creator.
Inside the Black Box: How Models Learn Patterns
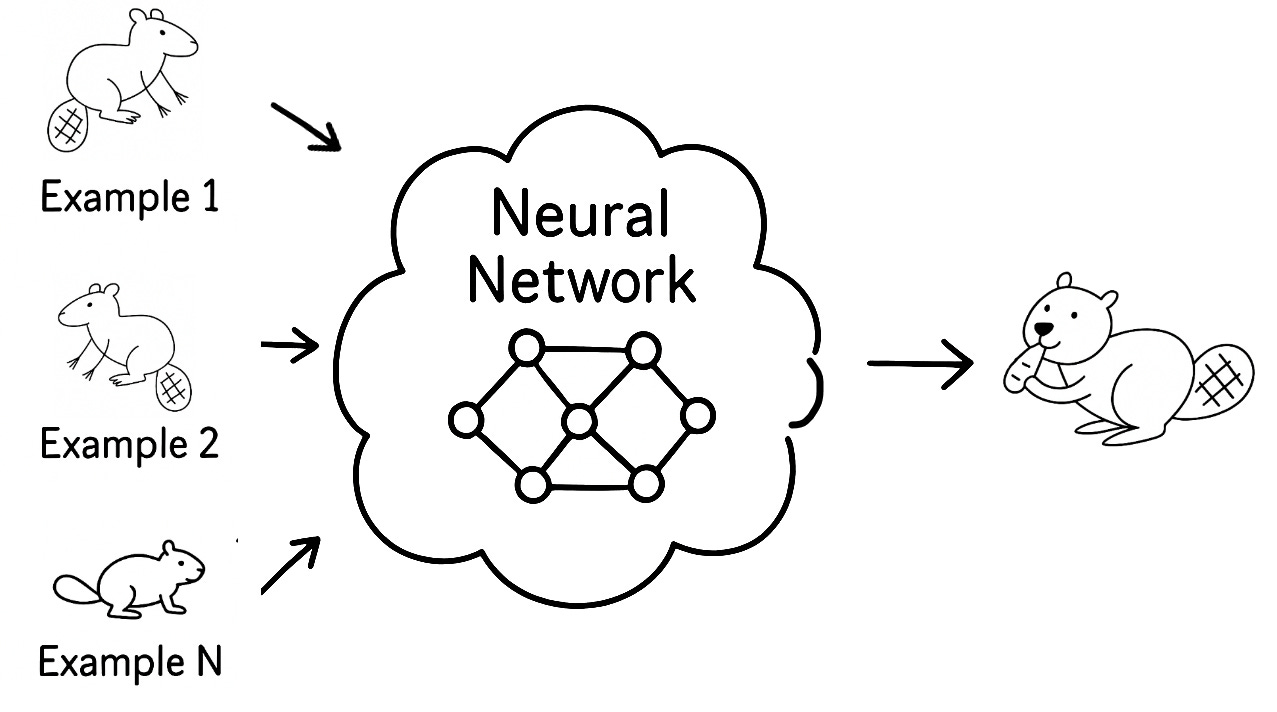
Generative AI trains huge neural networks, which are layers of tiny mathematical units that pass signals to one another and roughly echo how brain cells communicate, to spot patterns rather than rote answers.
During training, the network consumes vast collections of text, pictures, audio, and video, tallying how often words, shapes, or sounds appear together and in what order. Those tallies form an internal map of language rules, visual outlines, musical progressions, and motion cues, a kind of statistical gut feeling the model develops.
Later, when you ask it to write a bedtime story or draw a beaver eating a carrot, the system consults that map, blends familiar pieces into fresh combinations, and produces new material in seconds without copying any single example verbatim.
Meet the Big Three: VAEs, GANs, Diffusion
Generative models learn the overall “shape” of their training data, then pull fresh examples from that mental picture. In image and media generation today, three foundational generative approaches dominate practice: variational autoencoders (VAEs), generative adversarial networks (GANs), and diffusion models.
Because many technical textbooks can feel dense and intimidating, we will explain these models in clear, accessible language.
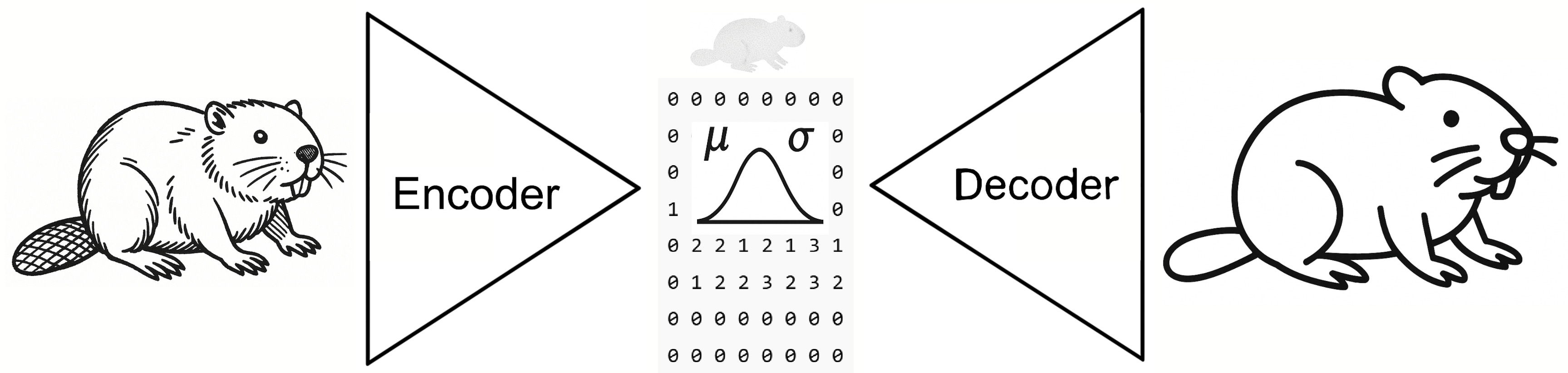
Variational autoencoders (VAEs): Imagine a zipper: the network squeezes data into a compact bundle of numbers, then unzips those numbers into something that looks familiar but is not an exact copy.
Under the hood (in jargon terms): A VAE has two parts.
Encoder: turns each input into a probability cloud inside a hidden, lower‑dimensional “latent” space.
Decoder: samples a point from that cloud and converts it back into data.
Training a VAE nudges both parts to keep the reconstructed output as close as possible to the original while still leaving room for small, creative shifts.
Generative adversarial networks (GANs): In this family of models, two neural networks play a repeated zero-sum game: the “generator” network creates non real (fake) items, and the “discriminator” network tries to tell non real from real items. Each round teaches the generator to fool the discriminator more effectively. Eventually, the quality of fake items becomes so high that neither the discriminator nor the human eye can distinguish what is real and what is not.

Diffusion models: Peeling off a scratch‑off ticket reveals hidden numbers bit by bit. Diffusion models learn the same stepwise unmasking. During training they do the reverse: layer static noise over real images until everything is gray. By rehearsing how to remove each layer, they learn the order. When generating, they start with pure noise, peel off layers, and produce a new picture.
Under the hood (the jargon terms): a diffusion model has two complementary processes.
Forward diffusion: takes a data sample, such as an image, and progressively corrupts it by adding small amounts of (Gaussian) noise in multiple steps.
Reverse denoising network: it seeks to undo this transformation by learning to gradually denoise the noisy data.
Some supplementary explanations:
During training, the model begins with a clear picture, for instance a photo of a beaver. Picture a volume knob labeled from 0 (perfectly clear) to 1,000 (pure static). For each training step the model twists that knob to a random setting, sprinkles the chosen amount of static onto the photo, and hands the noisy image to the neural network. The network's job is to figure out which static was added so it can subtract it and recover the original picture. After practicing on millions of photos, each fuzzed at every possible knob position, the model learns how to remove noise of any strength.
When the model creates something new, it runs the same steps in reverse. It starts with a canvas of pure static, gradually dials the noise volume down while applying its learned clean-up skill, and ends with a fresh, sharp image of a beaver or anything else the prompt requests.

Four Big Takeaways for Designers and Researchers
After exploring how VAEs zip data, how GANs pit a forger against a critic, and how diffusion models peel noise like a scratch-off ticket, we can distill four practical insights that every designer and researcher should keep in mind.
Generative models rely on patterns, not understanding: they capture statistical regularities from their training data, so every output needs a human reality check.
Randomness fuels both creativity and risk: injected noise can spark fresh ideas, yet a single result may miss the mark or contain errors.
Quality improves only through feedback: systems learn by having their mistakes flagged and corrected, which means review loops are essential.
Training data defines the outcome: beauty or bias in the source material flows straight into the results, so curate data sets carefully and craft prompts with intent.
These points can help designers and researchers leverage generative AI’s speed and variety while guarding against its blind spots.
Bringing it All Together
Thank you for staying with us. In this post we saw how generative AI has shifted computing from labeling content to creating it. We focused on three influential model families used across many media types, including images, audio, and video: variational autoencoders, generative adversarial networks, and diffusion models. Each family turns learned data patterns into new, realistic outputs in its own way. These systems work best as creative partners when they receive clear prompts and when humans review the results to catch errors and correct bias. Next week we will examine large language models to see how they are reshaping our interaction with text and information.
Reference
Bishop, C. M., & Bishop, H. (2024). Deep learning: Foundations and concepts. Springer. https://doi.org/10.1007/978-3-031-45468-4